

For decades, scientists have dreamed of giving a voice back to those who cannot speak. Today, that dream is rapidly becoming reality. Breakthrough brain-computer interfaces (BCIs) are now translating brain waves into speech, allowing people with paralysis to communicate in sentences at speeds approaching natural conversation. In this article, we explore recent breakthroughs in decoding brain activity into speech – focusing on milestone achievements from institutions like UC San Francisco (UCSF) and UC Berkeley, and new players in industry such as Precision Neuroscience and Neuralink. We’ll journey through a chronological overview of major advances, highlight case studies of patients regaining the ability to communicate, and explain the cutting-edge AI, neural decoding techniques, and devices fueling this revolution. Along the way, we’ll see how academic labs, startups, and government initiatives have converged to turn brainwaves into voice, achieving feats that were science fiction just a few years ago.
The idea of translating brain signals to speech has a long history. Early assistive communication devices for paralyzed patients (such as Stephen Hawking’s system) relied on slow, indirect methods – detecting eye blinks or tiny muscle movements to spell out words. Researchers envisioned a more direct path: reading electrical activity from the brain’s speech centers and converting it to words or sound. In the 2010s, foundational neuroscience research began cracking the code of speech in the brain, laying the groundwork for today’s advances.

One early breakthrough came in 2012 when scientists at UC Berkeley used implanted electrodes to reconstruct recognizable sounds from brain activity in the auditory cortex . By analyzing the neural signals of volunteers as they listened to words and music, they could digitally recreate the sounds the brain heard. This was a remarkable proof-of-concept – essentially “mind reading” of heard speech – and demonstrated that the electrical patterns in the brain carry rich information about audio and language. It set the stage for targeting the speech production process itself.
Throughout the 2010s, teams like Dr. Edward Chang’s lab at UCSF mapped how the brain controls the vocal tract during speech. They discovered that the brain doesn’t encode speech as a simple audio signal – instead, speech brain areas encode the movements of the lips, tongue, jaw, and larynx needed to produce sounds . As Chang explained, decoding speech would mean decoding those complex motor commands rather than just sound frequencies. Armed with this insight, researchers began building “virtual vocal tracts” – computer simulations of a human vocal apparatus – that could be driven by brain signals .
A major proof-of-principle arrived in 2019. Chang’s UCSF team created a brain-machine interface that generated natural-sounding synthetic speech from brain activity, using a virtual vocal tract controlled by neural signals . In this study (published in Nature), five volunteer patients with epilepsy – who still had normal speech – were implanted with a sheet of electrodes (an electrocorticography array) on the surface of the brain. As they read sentences aloud, the system learned to map their brain activity to the corresponding movements of the virtual vocal tract, and then to synthesize spoken sentences in the participants’ own voices .
This was the first time entire spoken sentences were produced from brain signals in real time. “For the first time, this study demonstrates that we can generate entire spoken sentences based on an individual’s brain activity,” said Dr. Edward Chang, senior author, calling it “an exhilarating proof of principle” . Although this 2019 experiment was done in people who could still speak (to validate the decoded speech against actual speech), the ultimate goal was clear: to restore voice to people who cannot speak due to paralysis or illness . The success of the virtual vocal tract approach – focusing on brain commands for articulating words – showed that fluid, naturalistic communication from neural signals was within reach.
Having shown that decoding speech from brain activity was possible, researchers turned to those who needed it most: patients who are paralyzed and unable to speak (a condition sometimes called being “locked-in”). In 2021, Dr. Chang’s team at UCSF made history again – this time with a volunteer who had lost his speech and mobility after a severe brainstem stroke nearly 15 years prior . They implanted a thin, flexible electrode array over the speech motor cortex of this man (identified as Bravo-1 in the study) and connected it to a machine-learning decoder. For the first time, a completely paralyzed person used neurotechnology to broadcast full words from his brain – not just spelling them out letter by letter, but producing entire words via a direct brain-to-text BCI .
In their pilot study (published in New England Journal of Medicine), the patient was limited to a 50-word vocabulary of basic words (yes, no, thirsty, etc.), which the system could recognize from his neural activity and output as text on a screen . It was slow – about a few words per minute – but it demonstrated an unprecedented capability. “It was the first time a paralyzed person who couldn’t speak had used neurotechnology to broadcast whole words – not just letters – from the brain,” Dr. Chang noted proudly . The participant, who previously had to spell out messages via a head-mounted pointer, could now produce simple sentences by attempting to say them and having the device decode his brain signals .
This achievement was the culmination of over a decade of research into the brain mechanisms of speech . It provided a glimpse of a future where loss of speech might not mean loss of voice. But it was just a start – the system’s speed and vocabulary were very limited. The race was now on to expand these capabilities.
Around the same time in 2021, another approach was exploring communication BCI for paralysis: a Stanford-led team asked a volunteer to imagine handwriting letters, rather than speaking, and decoded the neural signals to text. Using tiny implanted electrodes in the motor cortex of a man with paralysis, they achieved a record-breaking rate of 90 characters per minute (roughly 18 words per minute) by decoding imagined pen strokes . This demonstrated that alternative strategies (like tapping into the brain’s motor plans for writing) could also yield fast communication. While not speech per se, it underscored how combining BCIs with clever AI decoding could dramatically boost speed. The previous record for BCI communication speed had been on the order of a few words per minute; suddenly, an optimized system hit 18 WPM . Clearly, there was room to go much faster by leveraging machine learning and more brain signals.
Following the 2021 breakthroughs, researchers focused on making brain-to-speech BCIs more fast, accurate, and usable in conversation. Key challenges were to scale up from a tiny fixed vocabulary to large vocabularies (thousands of words), improve the recognition accuracy, and of course increase the words-per-minute throughput. Over the next two years, astonishing progress was made on all fronts, aided by more advanced AI algorithms and more sophisticated neural implants.
By mid-2020s, teams had begun integrating deep learning models that could decode the complex patterns of neural activity associated with speaking entire words and sentences. Instead of recognizing one of only 50 predefined words, the new systems started to interpret phonemes – the basic sound units – from brain signals, which could then be assembled into an unlimited range of words by a language model . This two-stage approach (neural signals → phonemes → words) vastly expanded flexibility. Researchers also employed powerful recurrent neural networks and language prediction algorithms to guess likely words, dramatically improving accuracy even with large vocabularies.
Crucially, the neural interface devices improved as well. In some studies, high-density electrocorticography (ECoG) arrays with hundreds of electrodes recorded stable signals from the speech cortex surface . In others, penetrating microelectrode arrays captured activity from individual neurons in speech-related areas . Each approach has pros and cons: ECoG grids cover a wider area and tend to remain stable over time, while intracortical electrodes can pick up finer details but may yield signals that drift. Researchers began to report that ECoG could offer more stable long-term decoding without daily recalibration – “the big advantage of ECoG is the stability we see,” explained Sean Metzger, a UCSF doctoral researcher, noting their decoder worked well even without retraining each day .
By 2023, the field had reached a tipping point. Multiple groups were now achieving communication rates of dozens of words per minute – a quantum leap from the 5–10 WPM of earlier assistive devices . The error rates (previously 50%+ for large vocabularies) were coming down into a workable range around 20–30% . This meant a user could attempt to say a sentence and most words would be correctly decoded, with only occasional need for correction. Perhaps most impressively, researchers began synthesizing whole spoken sentences with a voice – not just text. The stage was set for a pair of landmark demonstrations that would show the world just how far BCI speech technology had come.
In August 2023, two separate teams (one at Stanford University, one a UCSF/UC Berkeley collaboration) published back-to-back papers in Nature that shattered previous records and showed BCI speech prostheses working at conversational speeds . Each group, working with a paralyzed volunteer, demonstrated the ability to decode brain signals into fluent sentences in real time. While their approaches differed, the outcomes were strikingly similar – and truly groundbreaking.
Stanford Team (Henderson et al.) – “T12” Finds Her Voice: Jaimie Henderson and colleagues at Stanford worked with a participant (“T12”) who had advanced ALS, a disease that had left her unable to speak . They implanted two tiny electrode arrays in her motor cortex (in regions responsible for attempting to articulate speech) to record neural activity. Over a series of training sessions, T12 would attempt to say phrases, and a deep-learning algorithm learned to match neural patterns to phonemes (speech sounds) . Those phonemes were then decoded into words by a second algorithm. Using this method, the Stanford BCI could translate T12’s attempted speech at an average 62 words per minute, with a vocabulary of tens of thousands of words . This was over 3× faster than any previous BCI for communication. “The device achieved an average of 62 words per minute, more than three times as fast as the previous record of 18 WPM,” reported first-author Francis Willett . Encouragingly, Willett noted the speed limit was not the technology but the user: “The rate limit isn’t the algorithm… If we asked her to go as fast as she could… how much faster she could go is an open question.” . In other words, T12 might learn to communicate even faster with practice.
The Stanford BCI output the decoded words as text on a screen. In one demo, T12 was able to convey the sentence “Bring my glasses closer, please,” solely via her neural signals driving the system . Importantly, when they constrained the system to a small 50-word vocabulary, the word error rate was under 10% – and even with a large 125,000-word vocabulary, it remained around 23% . This showed that high accuracy is achievable, especially in limited contexts. The team’s use of a language model helped ensure that the stream of decoded phonemes formed intelligible words and sentences. For T12, who previously had to use a painstaking eye-tracking tablet to communicate, this meant a new freedom to express herself quickly and largely accurately.
UCSF/UC Berkeley Team (Chang & Anumanchipalli et al.) – “Ann” Speaks Again: In the companion study, a collaborative team led by UCSF neurosurgeon Edward Chang and UC Berkeley engineer Gopala Anumanchipalli worked with a woman named Ann who had been left mute and paralyzed by a brainstem stroke many years ago . They implanted a paper-thin ECoG electrode sheet with 253 channels over Ann’s speech motor cortex . Using a similar machine-learning approach, Ann’s neural activity while she attempted to speak was decoded into both text and audio output. In fact, this system went a step further: it drove a digital avatar – a talking face on a screen – that spoke in a voice modeled after Ann’s own pre-injury voice . Essentially, they gave Ann a virtual voice and face, allowing her to communicate with others in a more natural way.
The performance was unprecedented. Ann was able to communicate at 78 words per minute via the BCI – “which was faster than the Stanford team’s device and more than four times as fast as the previous record,” noted IEEE Spectrum’s report . Even with a large vocabulary (over 1,000 words), the system achieved about 75% accuracy (25% error rate), and with a smaller 119-word vocabulary it was over 90% accurate . For Ann, who had been limited to nods and an eye-tracking device, this meant being able to freely say anything that came to mind and have it spoken aloud almost instantly.
The team made use of AI in multiple ways. Because Ann could not produce any audible speech at all, they trained the decoder by having her attempt to silently mouth given phrases, and used a pre-trained text-to-speech model (plus recordings of her voice from before her stroke) to generate the audio for training and for the avatar’s voice . This innovative workaround meant the AI could “guess” what her voice would have sounded like for each attempt, allowing the system to learn the mapping from brain signal to intended speech without her ever speaking a word out loud. They also implemented a streaming decoding method – instead of waiting for an entire sentence’s worth of data, the system processes brain signals in real-time chunks, cutting latency dramatically. As of 2025, the team reported they could get the first sounds out within about 1 second of when Ann’s brain sent the signal, and stream continuous speech as she imagined speaking . “For the first time, we enabled near-synchronous voice streaming… The result is more naturalistic, fluent speech synthesis,” said Prof. Anumanchipalli of UC Berkeley , highlighting that they solved the long-standing problem of latency in speech BCIs .
Perhaps most moving was seeing Ann interact through the avatar. In a lab demonstration, as she sat connected to the BCI, her digital avatar appeared on a screen, speaking the words that her paralyzed lips could not. “I think the avatar would make them more at ease,” Ann said of how this technology might help her work with future counseling clients, expressing hope that regaining a voice could enable her dream career . For the researchers and family members present, it was a powerful moment: technology had bridged a gap that once seemed unbridgeable.
A participant who lost her ability to speak uses a BCI system that converts her neural activity into speech via a digital avatar on the screen (UCSF/UC Berkeley study). In 2023, this system achieved a breakthrough of 78 words per minute .
Experts hailed these 2023 results as a milestone for the entire field. Dr. Edward Chang, who was involved in the UCSF/Berkeley study, remarked in a press briefing that “Sixty to 70 WPM is a real milestone for our field in general because it’s coming from two different centers and two different approaches.” Two independent teams had shown that neural speech prosthetics can approach the low end of normal speech speed (normal conversational speech is ~150 WPM ). While still at roughly half the speed of natural speech, 60–78 WPM represents 5–6 times faster communication than the previous generation of assistive devices which max out around 10–15 WPM . And importantly, participants were forming sentences in their brain – the devices decoded what they intended to say, providing a fluid communication experience, rather than picking letters one by one.
The innovation hasn’t slowed down. In fact, the year after those Nature papers, yet another team pushed the envelope further. In 2024, researchers at UC Davis Health (as part of the multi-site BrainGate consortium) revealed a BCI that achieved astonishing accuracy in restoring speech for an ALS patient. Neurosurgeon David Brandman and neuroscientist Sergey Stavisky implanted four microelectrode arrays (256 electrodes total) in the speech motor cortex of a 45-year-old man, Casey Harrell, whose ALS had made his speech nearly unintelligible . Within minutes of turning the system on, Casey could convey his thoughts via text that the computer spoke aloud in his own former voice – recreated from old voice recordings .
In early tests, the UC Davis system reached 99% accuracy on a 50-word vocabulary after just 30 minutes of training . Even when they expanded to a massive 125,000-word vocabulary, it maintained around 97% transcription accuracy – the highest reported to date. “Previous speech BCI systems had frequent word errors… Our objective was to develop a system that empowered someone to be understood whenever they wanted to speak,” Dr. Brandman explained . This advance was enabled by training efficient machine-learning models that could learn from relatively little data, combined with an autocorrecting language model to ensure errors were rare . The result was that Casey could communicate immediately and reliably. “The first time we tried the system, he cried with joy as the words he was trying to say correctly appeared on-screen. We all did,” recalled Stavisky . In subsequent sessions, not only did the text appear, but a personalized voice synthesizer spoke the words in a recreation of Casey’s own voice, providing a deeply meaningful restoration of identity.
At UC Berkeley, meanwhile, researchers focused on eliminating lag in BCI speech. By March 2025, the UCSF-Berkeley team announced a new “streaming” BCI algorithm that produces continuous speech with almost no delay . In previous systems, a user had to pause while the device processed each sentence (often with a several-seconds delay). The new approach, reported in Nature Neuroscience, uses recent AI advances to stream decoded speech in near real-time. “Our streaming approach brings the same rapid speech decoding capacity of devices like Alexa and Siri to neuroprostheses,” said Prof. Anumanchipalli . By detecting the neural signal that signifies the intent to speak, the system can start producing audio within ~1 second of that signal . It also allows continuous output so that a person can keep speaking (in neural terms) without waiting for the device – making the experience much more natural and conversational . Notably, this advancement did not sacrifice accuracy compared to the earlier, slower method . As co-lead author Kaylo Littlejohn, a Berkeley PhD student, noted, this approach is device-agnostic – the same AI model could decode neural data from different types of sensors, even noninvasive ones, as long as the signal quality is sufficient . This opens the door to flexible BCI systems that might eventually work with less invasive tech.
With these ongoing developments, the gap between thinking and speaking via a device has narrowed considerably. In just a few years, we’ve gone from single-letter mind spelling to mind-to-speech systems that approach the speed, accuracy, and expressiveness of natural speech. Every few months seems to bring a new “first” – first 1,000-word vocabulary, first near-100% accuracy, first real-time voice, and so on. It’s an exhilarating time in neuroscience and AI, as long-standing challenges fall away one by one.
So, what makes it possible to decode speech from brainwaves? It’s a blend of advanced neuroscience, engineering and artificial intelligence. Let’s break down the key elements of the technology:
Tapping the Right Brain Regions: Speaking is a complex act, but it all starts in the brain. BCIs for speech typically target the motor cortex areas that control the vocal tract (sometimes along with nearby language-planning areas). In Ann’s and Casey’s cases, electrodes lay over the precentral gyrus, which controls movements of the larynx, mouth, and tongue . When these patients attempt to speak, neurons in these regions fire in patterns corresponding to the intended sounds. The BCI’s job is to capture those patterns. Brain Signals Acquisition: Two main technologies are used to record brain activity. One is electrocorticography (ECoG) – a sheet of electrodes placed on the surface of the cortex (under the skull, above the brain).
The ECoG picks up the summed activity of local neuron populations and is relatively stable over time . The other is intracortical microelectrodes – tiny silicon needle arrays that penetrate the cortex a few millimeters to record spikes from individual neurons. These can offer very high resolution (listening to single neurons or small clusters), but they are more invasive and can sometimes lose signal as neurons move or die back around the electrodes.
Stanford’s 2023 study used penetrating arrays, whereas UCSF’s used a high-density surface array . Each approach yields a rich stream of brainwave data – essentially hundreds of channels of voltage traces that fluctuate as the person thinks of speaking. Decoding with AI: Raw neural data is extremely complex – far too complex to decode with simple rules. This is where AI algorithms shine. Modern BCIs use deep neural networks (similar to those in speech recognition or translation) to find patterns in the brain signals. A common approach is to train a recurrent neural network or transformer model on the neural data paired with the sentences the person was attempting to say. The model “learns” the statistical relationships between neural activity patterns and particular phonemes/words . For example, a certain neural firing pattern might reliably correspond to the “mmm” sound, another to “ah”, etc. By learning sequences, the AI can predict likely phoneme transitions and output a stream of these units as the person tries to speak. Then, a second stage model (which could be another neural net or a decoding algorithm) converts the phoneme sequence into text – essentially spelling out the recognized words – and even into synthetic speech by feeding the text into a voice synthesizer. Many systems also incorporate a language model (LM) trained on English text to help autocorrect and predict words. If the neural decoder produces a sequence like “C A T”, the LM helps confirm that “cat” is a likely intended word in context. This greatly boosts accuracy, especially with large vocabularies .
Training the System: Initially, each BCI must be trained for the individual user. This involves a series of sessions where the person attempts to say specific words or sentences provided by the researchers. For instance, T12 (Stanford’s participant) spent ~25 sessions of ~4 hours each, trying to speak sample sentences so the AI could learn her neural patterns . Ann (UCSF/UCB participant) similarly went through training where she silently attempted given phrases . During training, the system knows what the target phrase is (either because the participant actually spoke it aloud if they can, or from a prompt on screen), so it can adjust the decoder’s parameters to reduce the error between the predicted output and the target. Recent advances have greatly reduced training time – e.g. the UC Davis team got high performance after only a couple of sessions (under 2 hours of data) , thanks to efficient algorithms and possibly leveraging pretrained models.
The goal is to eventually have BCIs that calibrate quickly or even work off-the-shelf, but we’re not quite there yet. Synthesizing Voice: Decoding the words is half the battle – the other half is giving a voice output. Some systems stick to text output on a screen, but newer ones generate spoken audio so that the communication feels more natural. This is done with text-to-speech (TTS) technology. In Ann’s case, they customized the TTS by training it on old voice recordings of her, to recreate a voice that sounded like her own . Casey’s team did similarly, using software to clone his pre-ALS voice . Thus, when the BCI outputs text, a voice synthesizer immediately speaks it in a familiar voice. The UCSF group even tied in a graphical avatar face that animates mouth movements to match the speech, making interactions more personal .
All of these pieces – high-quality neural signals, robust AI decoding, and realistic voice synthesis – must work together in real-time. The recent breakthroughs have come from optimizing each piece and getting the latency (delay) down to a second or less . It truly takes a convergence of fields: neuroscience provides the brain maps and electrode technology, electrical engineering builds the implant hardware and signal processors, and AI provides the computational models that translate brain data to language. When done right, the effect is almost magical: a person thinks of a sentence and hears it spoken aloud moments later.
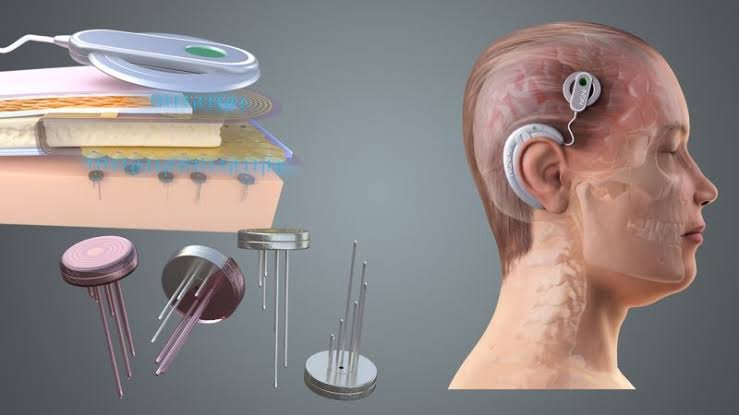
One cannot talk about BCIs without discussing the medical devices that make them possible. These breakthroughs rode on a wave of innovation in neural interface hardware. Here are some of the key technologies and players:
Utah Microelectrode Array: A bed-of-nails style silicon chip with ~100 tiny needle electrodes. This classic design (used in BrainGate trials) is what the Stanford team implanted in their ALS participant’s speech area. It penetrates the cortex a millimeter or two to record spikes. Utah arrays have enabled high-speed BCIs (like the handwriting-BCI and Stanford’s 62 WPM speech BCI) by providing very detailed signals. However, surgical implantation is more invasive (requires opening the skull and inserting into brain tissue), and each array covers only a few millimeters of cortex.
Also, signals can fluctuate as neurons move relative to the needles. Companies like Blackrock Neurotech manufacture these FDA-approved arrays and are working on wireless versions and higher channel counts for future BCIs. High-Density ECoG Grids: Instead of needles, ECoG uses flat electrode pads that sit on the brain surface. Traditional clinical ECoG grids (used for epilepsy mapping) have relatively sparse electrodes (~1 cm apart). But research groups have developed high-density versions with hundreds of electrodes spaced just a few millimeters or less apart. The UCSF team used a 253-electrode ECoG sheet covering a large part of the speech motor cortex .
A big advantage is stability – since it doesn’t penetrate the brain, the signals remain consistent day-to-day and the risk of damage is lower . ECoG can also cover a broader cortical area with one grid, potentially capturing multiple regions (useful since speech involves a network of areas). The downside is slightly less spatial resolution than penetrating electrodes, and it usually requires a wired connection through a percutaneous port (a connector on the head), which is not yet a fully implantable solution. Researchers are actively working on wireless ECoG transmitters and even on fully implanted ECoG units that could be permanent. Neuropixels and Other Advanced Microelectrodes: Beyond the Utah array, newer electrode technologies aim to increase channel count and longevity. For example, Neuropixel probes (developed for neuroscience research) pack hundreds of electrode contacts along a thin shank, potentially recording many neurons at different depths. While these haven’t been used in human BCIs yet, the trend is toward higher channel counts – from the hundreds to the thousands – to capture more information-rich brain data. More channels can mean decoding finer nuances of speech.
The challenge is making these devices safe and stable for chronic use in humans. Minimally Invasive BCIs (Stentrodes and Beyond): Not every breakthrough requires open-brain surgery. One notable device is the Stentrode from startup Synchron. This is a BCI electrode array mounted on a stent (a small metal mesh tube) that can be inserted into a blood vessel in the brain through a catheter (similar to a cardiac stent procedure). Synchron’s stentrode enters the jugular vein and is guided into a vein adjacent to the motor cortex. There, it expands and the electrodes on the stent contact the vessel wall, picking up neural signals from the brain without open surgery. Synchron has already tested this in a few ALS patients, enabling them to control a computer cursor and even send text messages by thought . In 2021, a patient with a Synchron stentrode was able to tweet just by thinking – a world first. While current stentrodes have lower bandwidth than invasive grids or arrays, the technology is advancing, and their big selling point is safety and ease: a less invasive implant procedure with no hole drilled in the skull. Next-Generation Thin-Film Arrays: Enter companies like Precision Neuroscience, co-founded by Dr. Benjamin Rapoport (a former Neuralink founding team member). Precision is developing an ultrathin, flexible electrode array called the Layer 7 Cortical Interface – named for the idea of a “seventh layer” on the surface of the brain (since the cortex has six layers of neurons) . Their device is like a flexible foil with 1,024 electrodes on a 1 cm² area . It’s so thin (one-fifth the thickness of a human hair) that it can conform to the brain surface without damaging it . Uniquely, Precision’s goal is to implant this through a small slit in the skull – a minimally invasive insertion – and it’s designed to be removable as well .
In 2023, Precision announced the first-in-human use of Layer 7 in a clinical study: surgeons at West Virginia University temporarily placed the sheet on the brains of patients undergoing tumor surgeries (with the patients awake) to map their language areas at unprecedented resolution . The device recorded signals successfully and helped identify critical speech regions. “It’s as if I was seeing the patient’s brain think,” said Dr. Peter Konrad of WVU, marveling at the high-res brain activity mapping . The broader vision is that such a device could be implanted in a paralyzed patient to restore functions like speech or limb control. Precision’s approach sits in between Synchron and Neuralink on the invasiveness scale – it’s not deep in the brain like Neuralink’s electrodes, but does require minor surgery to place on the cortex. Fully Implanted Wireless Systems: One limitation of current academic prototypes is that many require a wired connection (a plug on the head).
Companies are tackling this by creating fully implantable units with wireless telemetry. Neuralink, for example, has developed a sealed implant (the size of a large coin) that embeds fine, flexible electrode threads into the brain and wirelessly transmits data. Their device, called the N1 or Link, can have over 1,000 channels and is implanted via a robotic surgery system that threads the electrodes with precision. Neuralink has so far demonstrated its implants in pigs and monkeys – including a monkey moving a cursor and playing Pong with its mind, via two Links with 1,024 electrodes each in its motor cortex. In 2023, Neuralink received FDA clearance to begin its first human trials , aiming to test safety and efficacy in people with paralysis. While Neuralink has not published results on speech decoding yet, their high-bandwidth implant could be used for that purpose. Their stated initial goal is to enable text messaging or cursor use for paralyzed patients, which is closely related to the speech BCI objective.
In summary, a diversity of BCI hardware is emerging: from noninvasive wearables and implanted stents to high-density electrode sheets and sophisticated neural meshes. This hardware revolution is a crucial underpinning of the recent BCI achievements. As Dr. Chang noted, “it is exciting that the latest AI advances are greatly accelerating BCIs for practical real-world use” – but it’s equally true that advances in hardware (more electrodes, better stability) give the AI more to work with. Many teams are now talking about scaling to thousands of channels (to capture every nuance of brain activity) and covering multiple brain areas to improve context. The devices are also getting smaller, safer, and more ergonomic, moving toward systems that could be implanted long-term and used at home, not just in a lab.
The progress in neural speech decoding has been a collective effort, with crucial contributions from universities, companies, and government initiatives. Here we spotlight some of the major players and how this work is being funded and supported:
Academic Research Hubs: UCSF (Chang Lab) and UC Berkeley (Anumanchipalli Lab) have been at the forefront, collaborating on many of the breakthroughs described. Stanford University (Henderson/Shenoy group) has likewise led BCI development within the BrainGate consortium. UC Davis (Brandman/Stavisky) recently joined the ranks with their high-accuracy BCI. Other universities like Carnegie Mellon, Harvard/MGH, and Caltech also have teams working on related BCI challenges. These labs often work together and share advances; for example, Stanford’s and UCSF’s teams have exchanged ideas on decoder algorithms, and many team members have trained in the BrainGate consortium which spans multiple institutions.
The BrainGate Consortium: This is a long-running academic collaboration funded by the U.S. government (NIH and Department of Veterans Affairs) that has conducted BCI clinical trials for nearly two decades. BrainGate’s early trials provided the implants and infrastructure that made many later breakthroughs possible. For instance, both the Stanford 2023 study and the UC Davis 2024 study were part of the BrainGate clinical trial program . BrainGate participants are often coded as “T” plus a number (e.g., T5 was a famous participant in the 2010s, T12 in 2023). The consortium has been a cornerstone of BCI research, supported by grants from the National Institutes of Health. In fact, the 2023 Nature papers acknowledged support from the NIH BRAIN Initiative, a federal program launched in 2014 to fund high-impact neuroscience – including grants specifically for neuroprosthetic speech research .
The National Institute on Deafness and Communication Disorders (NIDCD) is noted as a supporter of the recent UCSF/UC Berkeley work . Government Agencies: Beyond NIH, agencies like DARPA (Defense Advanced Research Projects Agency) have catalyzed BCI tech. DARPA funded early work on “silent speech” interfaces for soldiers and on high-density brain interfaces (programs like SUBNETS and Neural Engineering System Design). While defense-related, these programs often spur fundamental tech useful for patients. For instance, DARPA’s support was instrumental in the development of high-channel-count BCIs and in fostering public-private partnerships in neurotech. Additionally, the FDA has a role – via its Breakthrough Device Program, it has given expedited review to devices like Synchron’s stentrode and Neuralink’s Link, recognizing their potential to address unmet medical needs (e.g., severe paralysis). Startup Companies:
Private companies are investing heavily to translate lab prototypes into real-world products. We’ve mentioned several: Neuralink (founded 2016) – Backed by Elon Musk, it has raised over $300 million to develop its sewing-machine-inserted brain implants . Neuralink built on decades of academic work but pushed the engineering of high-density, wireless implants. By 2023 they secured FDA approval for human trials , a sign of institutional support for moving BCI to commercial therapy. Their vision includes not just restoring speech and movement, but even higher-bandwidth applications down the line. Precision Neuroscience (founded 2021) – This company took a slightly different tack with its thin-film Layer 7 device. Precision has drawn significant venture funding (over $150 million by 2023) to advance its technology . In early 2023, it closed a $41M Series B and a $102M Series C round, attracting investors who see its minimally invasive approach as promising . “Precision’s technology has the potential to redefine the standard of care in clinical neuroscience,” said co-founder Dr. Rapoport .
The company is working closely with academic partners (like WVU’s Rockefeller Neuroscience Institute) to validate the tech in surgical settings . By 2025, reports emerged that Precision also received FDA clearance to use its implant for short-term brain monitoring, paving the way for therapeutic use. Synchron (founded 2016) – This startup gained an edge by being first to implant a BCI in a human without open brain surgery. Its stentrode received an FDA Breakthrough Device designation and began U.S. clinical trials in 2021 (after first-in-human tests in Australia). Synchron has also drawn tens of millions in funding, including investment from the likes of Bill Gates. They are targeting a communication BCI for paralysis that might be more easily adopted clinically due to the minimally invasive implantation.
Paradromics (founded 2015) – Another neurotech company developing high-channel-count implants (their device uses bundles of microwires to reach thousands of neurons). Paradromics raised significant funding and announced a system called Connexus with the aim of commercializing BCIs for speech and other applications. They haven’t yet tested in humans but are part of the competitive landscape pushing the technology forward. Blackrock Neurotech – Not a startup per se (it’s an established neurotech firm), Blackrock provides a lot of the baseline hardware (Utah arrays, signal processors) used in academic research. They’ve launched an initiative to bring a commercial BCI to market for paralysis under the trademark “MoveAgain”, and have mentioned plans to have dozens of patients using BCIs at home in the near future. Their role is a reminder that translational support from industry is key – turning experimental setups into reliable medical devices. Funding and Philanthropy: The breakthroughs we see are often underwritten by significant funding.
The UCSF 2019 study, for example, acknowledged support from NIH (grants DP2 OD008627, U01 NS098971), as well as the Howard Hughes Medical Institute and various foundations . Philanthropic organizations (like the McKnight Foundation and the New York Stem Cell Foundation) have backed high-risk, high-reward neurotech research. Tech companies have also played a role – notably, Facebook Reality Labs in the late 2010s funded part of Chang’s research into a “typing by brain” interface (Facebook’s project has since wound down, but it injected early funding that yielded valuable insights). Government grants via the BRAIN Initiative have been pivotal for academic teams, ensuring steady support for multi-year BCI trials that venture capital might deem too slow or uncertain. As we look at current developments, it’s clear that a healthy mix of public funding, private investment, and philanthropy is propelling this field. Each breakthrough paper typically lists a dozen funding sources – a testament to the broad base of support and the recognized importance of this work.
Clinical and Institutional Support: Medical centers like Stanford Hospital, UCSF Medical Center, and VA hospitals have provided the clinical infrastructure for these trials – from neurosurgeons willing to perform implant surgeries, to neurologists, speech therapists, and engineers collaborating in patient care. Universities are fostering interdisciplinary centers (e.g., the UC Berkeley-UCSF joint program in computational precision health) that bridge engineering and medicine. Even regulators and ethicists at institutions have helped by approving these experimental procedures under careful ethical guidelines, ensuring patients are protected and truly benefit. While we won’t delve into ethics here, it’s worth noting that the participants often express profound appreciation – they are true pioneers, volunteering for risky research in hopes of helping themselves and others. Their courage and dedication, along with family support, is an unsung element enabling these advances.
In short, the progress in translating brainwaves to speech is not due to one lone genius or a single company – it’s an ecosystem of innovation. University labs making discoveries, companies engineering solutions, government grants fueling research, investors betting on the future, and patients and clinicians teaming up in trials. This collaborative network is accelerating us toward a future where loss of speech might be swiftly remedied by a brain implant and a smart algorithm.

In the span of just a few years, what once seemed like a sci-fi fantasy – speaking through a brain implant – has become an tangible reality. Patients who have spent years unable to communicate beyond basic yes/no signals are now spelling out sentences, conversing in paragraphs, and even hearing their own voices speak again, courtesy of BCIs. The chronological journey from early experiments to the latest breakthroughs shows a stunning acceleration: from a 50-word prototype in 2021 to fluent 1,000-word vocabularies at 70+ WPM in 2023, and then to nearly error-free, real-time voice in 2024–2025. Each milestone built on the last, with improvements in algorithms and hardware compounding to reach performance levels that would have been implausible a decade ago.
Importantly, these achievements are bringing back more than just words. They restore a core piece of identity and human connection – the ability to freely express one’s thoughts and personality. As one participant put it, seeing her words spoken by an avatar “would make them more at ease” in talking with her, breaking the awkward silence that had walled her off . A research paper can report WPM and error rates, but the true impact is felt when a father with ALS can joke with his family again using a device, or a stroke survivor can say “I love you” in her own voice. We are witnessing the birth of a new kind of medical prosthesis: not one that restores movement to a limb, but one that restores the power of speech.
There is still work ahead to refine these systems for everyday use – making the implants fully implantable without wires, improving the convenience and reliability, and ultimately getting regulatory approval for widespread clinical deployment. Those topics are beyond our scope here, but suffice it to say, researchers and companies are actively working on them. The remarkable support from NIH, companies like Neuralink and Precision, and many others suggests that momentum is strong. As Dr. Ali Rezai of WVU noted, the potential of BCIs has long been discussed but only now being realized, and “innovations such as this from Precision Neuroscience are a key step forward” in bringing this technology to patients.
For now, it’s worth celebrating how far we’ve come. A synergy of neuroscience and AI has unlocked the ability to decode the human voice from brain signals, giving hope to countless individuals with paralysis or neurological disease. Every new breakthrough in this space not only pushes technical boundaries but also highlights the resilient human desire to communicate. In a very real sense, these BCIs are amplifying the voices of those who were silent, letting their thoughts be heard again. And that is a profound breakthrough in its own right – one that speaks to the heart of human dignity and connection.

